Introduction
A social network analysis of a small network that is involved in the Collaborative for Equitable and Inclusive STEM Learning (CEISL) Family as Faculty as an Infrastructure project at the Indiana University School of Education-Indianapolis. Funded in part by a National Association for Family, School, and Community Engagement Mini-Grant.
We are exploring the following questions through a social network analysis:
- What intentional social networks form through an effort between pre-admissions teacher education students, Neighborhood Caucus members, and Family Leaders through a Family as Faculty initiative focused on educational justice?
- Considering the social network as a model, what dynamics can be uncovered that provide insight into the ways in which connections and relationships are built through a Family as Faculty initiative focused on educational justice?
- Understanding the unruly complexity of educational justice work and the networks that emerge, what historical and social impacts can be brought forward to illuminate and deepen our understanding of how dynamic social networks operate while focusing on educational justice?
The term intentional social networks comes from the work of Kira Baker-Doyle that demonstrates how educators strategically reach out and construct networks around their work (Baker-Doyle 2012; Baker-Doyle and Yoon 2020). Unruly complexity comes from the work of Peter Taylor through his critique of models and his efforts to re-situate model-based research in historical and sociocultural contexts (Taylor 2010, 2018).
Components
All components of this work can be found at the project’s OSF repository.
File Structure
fafi-sna/
┣ assets/ <- Directory for storing auxiliary files
┃ ┗ fafi-sna-references.bib <- Bibliography for this project in BibTeX format
┃ ┗ theme.css <- Cascading style sheet for the project
┃ ┗ fafi-sna-logo.png <- Project logo
┃ ┗ credit.xml <- Author contributions in a JATS XML file
┣ docs/ <- Directory for the rendered literate programming file
┃ ┗ index.html <- Rendered version of the literate programming file
┣ index_cache/ <- Directory used to serve the rendered literate programming file
┣ index_files/ <- Directory used to serve the rendered literate programming file
┣ output/ <- Target directory for collecting R output files
┃ ┗ plots/ <- Directory for storing plots in PDF and PNG formats
┃ ┗ csv/ <- Directory for storing CSV files
┣ R <- Directory for storing R scripts
┃ ┗ fafi-sna.R <- R script distilled from the literate programming file
┣ .gitignore <- Files and directories to be ignored by Git
┣ .nojekyll <- File to tell Github to not use Jekyll
┣ _footer.html <- The footer for the rendered literate programming file
┣ _site.yml <- Configuration file for the rendered literate programming file
┣ CODE_OF_CONDUCT.md <- Code of Conduct for project contributors
┣ LICENSE <- License (MIT) for project
┣ README.md <- This file, a general overview of this project
┗ index.Rmd <- Literate programming file for the project analysisLiterate Code
Computer scientist Don Knuth (1984) first coined the term “literate programming” to describe a form of programming that is created as a human-readable narrative. It has been taken up as a format that is rich in comments and documentation to illustrate and illuminate the choices and decisions that were made in the act of programming. Literate code is also an essential aspect of research to promote reproducibility of analysis (Dekker 2018; Vassilev et al. 2016). In this case, as a community-engaged study, we are more interested in exemplifying trust, transparency, and accountability (Chou and Frazier 2020; Mullins et al. 2020; Sabatello et al. 2022), literate code provides a clear window for community members and participants into the inner processes of data analysis and visualization methodologies.
This is primarily an exercise in coding as bricolage (Lévi-Strauss 1968; Turkle and Papert 1992), so the code itself is neither particularly DRY nor SLAP. But it works and gets the job done even if there may be more elegant and efficient ways of doing things.
Load Libraries
Libraries are packages that are loaded in to extend the functionality to the base R programming language. This project makes use of three different categories of libraries: Network Graph Libraries, a Quantitative Anthropology Library, and Other R Libraries.
Network Graph Libraries
Network Graph Libraries allow for the construction, analysis, and visualization of
social network data. The igraph library (Csardi and Nepusz 2006) is the main social network
analysis engine, while tidygraph (Pedersen 2023) and ggraph (Pedersen 2022)
provide functionality for processing and visualizing social network graphs, respectively. Centiserve (Jalili 2017) provides extended centrality
algorithms.
Quantitative Anthropology Library
Since participants are asked for names and roles, the data collection process is
essentially a freelisting protocol (Quinlan 2018). Under that
assumption, Smith’s Salience (S) Score can be calculated. AnthroTools (Purzycki and Jamieson-Lane 2017)
provides functionality for working with freelist data and calculating Smith’s S.
library(AnthroTools)Other R Libraries
The other libraries utilized for this analysis provide extensions for base R in
working with data. The readr package (Wickham, Hester, and Bryan 2023) allows for efficient and
straightforward reading and writing of local CSV files,
while the rio (Chan et al. 2021) package allows for the reading of web-based CSV files as the datasets for this project are stored in an OSF repository. The glue (Hester and Bryan 2022), tidyr (Wickham, Vaughan, and Girlich 2023), and dplyr (Wickham et al. 2023)
packages are used to process data. The ggthemes package (Arnold 2021)
provides extended theme options for graphs, vistime (Raabe 2022) provides functionality
for creating timelines, ggcorrplot (Kassambara 2022) provides functionality for
creating correlation plots, and ggpubr (Kassambara 2023) provides functionality for creating
publication-ready plots and graphs.
Define Constants
The following constants are utilized across the project.
Common Color Pallete
The IBM Carbon Design System color pallete, a large
color-blind friendly data-oriented color palette, is used to represent various types of
participants. the_palette links these participant types with color codes.
the_palette <<- c(
"FL" = "#6929c4", "NC" = "#1192e8", "PA" = "#005d5d",
"CF" = "#9f1853", "FF" = "#fa4d56", "IL" = "#570408",
"OR" = "#198038", "OT" = "#002d9c", "SA" = "#ee538b",
"ST" = "#b28600", "UA" = "#009d9a", "UF" = "#012749",
"US" = "#8a3800"
)Participant Abbreviation List
Relatedly, the_abbrev dataframe provides links between the abbreviations for the
participant types and the full descriptions of these participant types.
the_abbrev <<- data.frame(
color_code = c(
"FL", "NC", "FF", "IL", "OR", "OT", "SA",
"ST", "UA", "UF", "US", "PA", "CF"
),
full = c(
"Family Leader", "NC Member", "Friend/Family",
"Institutional Leader", "Other Resource", "Therapist",
"Administrator", "Teacher", "Advisor", "Faculty",
"Staff", "Student", "Child"
)
)Define Functions
Functions provide “shortcodes” for repeating calculations or analyses multiple times with different variables, datasets, or networks.
Helper Functions
Helper functions provide functionality to other functions or ongoing analysis and calculations across the code.
Save Plots Function
This function saves plots to the output folder in two formats,
as a pdf file and as a png. These two formats serve different purposes, so both are useful:
pdf files are useful for inclusion in publications and png files are useful for distribution
via the web. Both files are set at a high resolution 300dpi.
plot_save <- function(the_plot, the_file) {
# Set the filename for the PDF.
pdf_name <- glue("output/plots/{the_file}.pdf")
# Set the filname for the PNG.
png_name <- glue("output/plots/{the_file}.png")
# Save as PDF.
ggsave(the_plot,
filename = pdf_name,
width = 11.5,
height = 8,
units = "in",
dpi = 300
)
# Save as PNG.
ggsave(the_plot,
filename = png_name,
width = 11.5,
height = 8,
units = "in",
dpi = 300
)
}Create Correlation Plot Function
Correlation plots are effective modes of visualizing relationships between variables. This function takes in a dataframe and creates and saves a correlation plot while identifying (with an X) correlations that are not statistically significant (i.e., the \(p\)-value for non-significant correlations is greater than 0.05).
plot_corr <- function(the_frame, the_file) {
# Calculate the correlation of the provided dataframe.
corr <- round(cor(the_frame), 1)
# Calculate a matrix of significance.
p_mat <- cor_pmat(corr)
# Initialize plot.
corr_plot <- ggcorrplot(corr,
hc.order = TRUE, # Order according to hierarchical clustering.
type = "lower", # Only display the bottom half.
p.mat = p_mat, # Account for statistical significance.
colors = c("#750e13", "#ffffff", "#003a6d")
) # Set colors.
# Save the plot...
plot_save(corr_plot, the_file)
# ...and return it.
return(corr_plot)
}Calculate Tukey’s Fences Function
Small graphs are prone to extreme outliers, especially when there are power dynamics such as instructor-student relations. While acknowledging this dynamic, it does skew such calculations as a Key Actor Analysis. Tukey’s fences (Hoaglin, Iglewicz, and Tukey 1986; Tukey 1993) is one way to remove the impact of these outliers.
calculate_tukey <- function(the_cent) {
# Calculate Tukey's fences
q <- quantile(the_cent, c(0.25, 0.75))
iqr <- q[2] - q[1]
the_fence <- data.frame(
lower = q[1] - 1.5 * iqr,
upper = q[2] + 1.5 * iqr
)
return(the_fence)
}Network Graph Functions
Initialize Network Graph Function
The set_graph function takes in an edge list that
provides a representation of who participants named in the survey and converts it into a
network graph object. Extra variables are added to the graph:
weight, which is the number of times \(i\) (the participant) names \(j\) on the survey, which is used to weight the relationships between actors.color_code, which is just the first two letters of actor id that allows reference to the color palette to set the color of the node when the graph is plotted.size_code, which is the Smith’s Salience Score for \(j\) (multiplied by 100) to set the size of the node when the graph is plotted.label, which is the abbreviation expanded with the ID number for easier reading when the graph is plotted.
The graph and these variables are passed on for plotting and calculating centralities. Several
of the centrality algorithms account for weight when calculating the centrality.
set_graph <- function(the_frame, the_salience) {
# Reduce the edge list to just i (from) and j (to).
the_frame <- the_frame |>
select("from", "to")
# Calculate the number of times i names j.
the_weight <- the_frame |>
group_by(from, to) |>
summarize(weight = n()) |>
ungroup()
# Combine the dataframes into one, matching the weight to the edge.
the_frame <- merge(the_frame, the_weight, by = c("from", "to"))
# Create the igraph object, and set it to be a directed graph (i.e., i -> j).
the_graph <- the_frame |>
graph_from_data_frame(directed = TRUE)
the_salience <- the_salience |> rename("name" = "actor")
node_data <- data.frame(name = V(the_graph)$name) |>
mutate(id_no = substr(V(the_graph)$name, 3, 4)) |>
mutate(color_code = substr(V(the_graph)$name, 1, 2)) |>
left_join(the_salience) |>
left_join(the_abbrev) |>
mutate(label = glue("{full} {id_no}")) |>
replace_na(list(SmithsS = 0.01))
V(the_graph)$color_code <- node_data$color_code
V(the_graph)$size_code <- (node_data$SmithsS) * 100
V(the_graph)$label <- node_data$label
# Send the graph object back for further processing.
return(the_graph)
}Plot the Graph Function
The draw_graph creates the visualization–the plot–of the
social network graph and then saves it for further use. The geom_edge_fan
feature is used to represent the number of times a participant named an actor.
draw_graph <- function(the_graph, the_file) {
# Set the filename for saving the graph.
the_file <- glue("sna_{the_file}-plot")
# Set a reproducible seed for randomization, used to ensure that the plot looks more or less
# the same each time it is created.
set.seed(123)
# Create the plot.
the_plot <- the_graph |>
ggraph(layout = "fr") + # Display the graph using the Fruchterman and Reingold algorithm.
geom_edge_fan(color = "#A7A9AB") + # Plot the edges between nodes.
geom_node_point(
aes(
color = color_code, # Plot the nodes with the color determined by the
linewidth = size_code
), # participant and the size of the node determined
show.legend = FALSE
) + # by the Smith's S Salience Score.
scale_size_continuous(range = c(2.5, 10)) + # Rescale the node size.
scale_color_manual(values = the_palette) + # Bring in the color palette.
geom_node_text(aes(label = label), repel = TRUE) + # Place the actor name on the graph.
labs(
edge_width = "Letters",
title = "Social Network",
caption = "Test caption"
) +
theme_few() +
theme(
axis.text = element_blank(),
axis.ticks = element_blank(),
axis.title = element_blank(),
panel.border = element_blank()
)
# Save the plot.
plot_save(the_plot, the_file)
# Return the plot for further use as necessary.
return(the_plot)
}Calculate Network Centralities Function
A number of node-level centralities, or metrics, are calculated on the graphs and are utilized for the analysis. Nodes are the graphical representation of actors and edges are the graphical representation of relationships between actors.
- Degree (In) Centrality. The number of incoming edges from other actors (Borgatti and Brass 2019; Everett and Borgatti 1999).
- Degree (Out) Centrality. The number of outgoing edges to other actors (Borgatti and Brass 2019; Everett and Borgatti 1999).
- Laplacian Centrality. The “what will happen when I’m gone” centrality, an indication of how indispensible an actor is based on the structural resilience of the network and how the network can “fill in” if a node is removed (Qi et al. 2012).
- Latora Closeness Centrality. A measure of efficiency of network graphs, particularly small and potentially disconnected graphs, indicating how efficiently information moves through the actor and across the network (Latora and Marchiori 2001).
- Leader Rank Centrality. A measure of influence, identifying actors who facilitate the rapid and wide spread of information across the network, an algorithm developed specifically for social networks rather than similar algorithms designed for web pages (Lü et al. 2011).
- Leverage Centrality. A measure of how “in the thick of it” an actor is, based on who they are connected to and who those actors are connected to, while accounting for parallel, not just serial, flows of information (Joyce et al. 2010).
calculate_centrality <- function(the_graph, the_salience, the_file) {
analysis_network_data <- data.frame(
indegree = igraph::degree(the_graph, mode = "in"),
outdegree = igraph::degree(the_graph, mode = "out"),
leaderrank = leaderrank(the_graph),
laplace = laplacian(the_graph),
leverage = leverage(the_graph),
latora = closeness.latora(the_graph)
)
analysis_network_data$actor <- rownames(analysis_network_data)
rownames(analysis_network_data) <- NULL
analysis_network_data <- analysis_network_data |>
select(actor, everything()) |>
left_join(the_salience) |>
replace_na(list(SmithsS = 0))
rownames(analysis_network_data) <- analysis_network_data$actor
return(analysis_network_data)
}Calculate Named Actors Salience Scores Function
calculate_salience <- function(the_frame, the_grouping, the_file) {
the_filename <- glue("output/csv/salience_{the_file}.csv")
anthro_frame <- the_frame |>
select("Subj" = "from", "Order" = "order", "CODE" = "to", "GROUPING" = "question") |>
add_count(Subj, GROUPING) |>
filter(n > 1)
if (the_grouping == "none") {
anthro_frame <- anthro_frame |>
select("Subj", "Order", "CODE") |>
distinct() |>
as.data.frame()
anthro_frame$Order <- as.numeric(anthro_frame$Order)
the_salience <- CalculateSalience(anthro_frame)
} else {
anthro_frame <- anthro_frame |>
select("Subj", "Order", "CODE", "GROUPING") |>
distinct() |>
as.data.frame()
anthro_frame$Order <- as.numeric(anthro_frame$Order)
the_salience <- CalculateSalience(anthro_frame, GROUPING = "GROUPING")
}
code_salience <- SalienceByCode(the_salience, dealWithDoubles = "MAX")
write_csv(code_salience, the_filename, append = FALSE)
code_salience <- code_salience |>
select("actor" = "CODE", "SmithsS")
return(code_salience)
}Key Actor Functions
Identify Key Actors Function
calculate_keyactors <- function(the_frame, the_file) {
max_leverage <- max(the_frame$leverage, na.rm = TRUE)
min_leverage <- min(the_frame$leverage, na.rm = TRUE)
key_frame <- the_frame %>%
select(actor, leverage, leaderrank, SmithsS)
key_res <- lm(leaderrank ~ leverage, data = key_frame)$residuals |>
as.data.frame() |>
rename(res = 1) |>
mutate(res = abs(res))
key_res$actor <- row.names(key_res)
row.names(key_res) <- NULL
key_frame <- key_frame |>
left_join(key_res)
leaderrank_fence <- calculate_tukey(key_frame$leaderrank)
key_frame_leaderrank_trimmed <- key_frame |>
filter(leaderrank >= leaderrank_fence$lower & leaderrank <= leaderrank_fence$upper)
leverage_fence <- calculate_tukey(key_frame$leverage)
key_frame_leverage_trimmed <- key_frame |>
filter(leverage >= leverage_fence$lower & leverage_fence$upper)
key_ymean <<- mean(key_frame_leaderrank_trimmed$leaderrank)
key_xmean <<- mean(key_frame_leverage_trimmed$leverage)
key_frame <- key_frame |>
mutate(keystatus = case_when(
(leaderrank > key_ymean & leverage > key_xmean) ~ "Sage",
(leaderrank > key_ymean & leverage < key_xmean) ~ "Steward",
(leaderrank < key_ymean & leverage > key_xmean) ~ "Weaver"
)) |>
na.omit() |>
group_by(keystatus) |>
arrange(desc(res), desc(SmithsS)) |>
unique() |>
ungroup()
key_frame <- key_frame |>
select(actor, leverage, leaderrank, res, SmithsS, keystatus) |>
arrange(keystatus, desc(res), desc(SmithsS))
return(key_frame)
}Plot Key Actors Function
plot_keyactors <- function(key_frame, the_file) {
the_filename <- glue("keyactors_{the_file}-plot")
key_xmin <- min(key_frame$leverage)
key_xmax <- max(key_frame$leverage)
key_ymin <- min(key_frame$leaderrank)
key_ymax <- max(key_frame$leaderrank)
steward_count <- count_keyactors(key_frame, "Steward")
sage_count <- count_keyactors(key_frame, "Sage")
weaver_count <- count_keyactors(key_frame, "Weaver")
key_frame <- key_frame |>
mutate(color_code = substr(key_frame$actor, 1, 2)) |>
mutate(id_no = substr(key_frame$actor, 3, 4)) |>
left_join(the_abbrev) |>
mutate(label = glue("{full} {id_no}")) |>
select(-full, -id_no)
key_plot <- ggscatter(key_frame,
x = "leverage", y = "leaderrank",
label = "label", label.rectangle = FALSE, repel = TRUE,
theme = theme_minimal(), ylab = "Leader Rank Centrality",
xlab = "Leverage Centrality", point = TRUE, show.legend = FALSE,
color = "color_code", palette = the_palette,
conf.int = FALSE, cor.coef = FALSE, legend = "none"
)
if (steward_count != 0) {
key_plot <- key_plot +
geom_vline(xintercept = key_xmean, color = "#243142", alpha = 0.2) +
geom_label(aes(x = key_xmin, y = key_ymax, label = "Stewards", hjust = 0),
color = "#243142", fill = "#A7A9AB"
)
}
if (weaver_count != 0) {
key_plot <- key_plot +
geom_hline(yintercept = key_ymean, color = "#243142", alpha = 0.2) +
geom_label(aes(
x = key_xmax, y = key_ymin,
label = "Weavers", hjust = 1
), color = "#243142", fill = "#A7A9AB")
}
key_plot <- key_plot +
geom_label(aes(
x = key_xmax, y = key_ymax,
label = "Sages", hjust = 1
), color = "#243142", fill = "#A7A9AB") +
theme_few() +
theme(legend.position = "none")
plot_save(key_plot, the_filename)
return(key_plot)
}Count Key Actors Function
count_keyactors <- function(key_frame, the_actor) {
the_count <- key_frame |>
count(keystatus) |>
filter(keystatus == the_actor) |>
pull(n)
the_count <- ifelse(is.numeric(the_count), the_count, 0)
the_count <- the_count |> replace_na(0)
return(the_count)
}Process Key Actor Data Functions
Deeper Analysis Functions
Combine Multiplex Graph Layers Functions
create_q_cent <- function(the_1, the_2, the.question) {
the_q_cent <- bind_rows(the_1, the_2) |>
mutate(question = the.question) |>
select(
question, actor, outdegree, indegree, leverage,
laplace, leaderrank, latora, SmithsS
)
}
calculate_ranks <- function(the_cent) {
the_cent <- the_cent |>
mutate(outdegree_rank = dense_rank(desc(outdegree))) |>
mutate(indegree_rank = dense_rank(desc(indegree))) |>
mutate(leverage_rank = dense_rank(desc(leverage))) |>
mutate(laplacian_rank = dense_rank(desc(laplace))) |>
mutate(leaderrank_rank = dense_rank(desc(leaderrank))) |>
mutate(smiths_rank = dense_rank(desc(SmithsS))) |>
mutate(latora_rank = dense_rank(desc(latora))) |>
select(
question, actor, outdegree, outdegree_rank, indegree, indegree_rank,
leverage, leverage_rank, laplace, laplacian_rank,
latora, latora_rank, leaderrank, leaderrank_rank, SmithsS, smiths_rank
) |>
arrange(question, actor)
rownames(the_cent) <- NULL
return(the_cent)
}Calculate Situational Flexibility Score Functions
Calculate Jaccard Index Function
The Jaccard Similarity Index is a measure of how similar two sets of information are, with a range between 0 (nothing is the same) and 1 (everything is the same).
\(J\), the Jaccard Similarity Index, is calculated with the following formula:
\(J(p,q) = \frac{|p \cap q|}{|p \cup q|}\)
where \(p\) and \(q\) are sets of information. The absolute value of the union of \(p\) and \(q\), or the number of items they have in common, is divided by the absolute value of the intersection of \(p\) and \(q\), or the number of total unique items across the both sets.
This value is then passed back to the Situational Flexibility Score \((f_S)\) function for further processing.
Calculate Situational Flexibility Score Function
The Situational Flexibility Score \((f_S)\) builds upon the standard community-based flexibility score (Porter 2014). In this case, situational flexibility refers to is a measure of the breadth of connections actors have to address situational information needs. Expanding upon the in degree and out degree centralities, situational degree looks at degree measures in a nuanced manner over the layers of a situation-oriented multilayered network graph.
The Actor Situational Flexibility Score is calculated with the following formula:
\(f_S = 1 - (\frac{\frac{1}{m(m-1)} \sum_{p\neq q} J(set_p,\ set_q)}{\max_{p,q} J(set_p,\ set_q)})\)
where \(m\) is the total number of sets, \(p\) and \(q\) represent the sets, and \(J\) represents the Jaccard Index. The calculation proceeds by dividing the sum of the Jaccard Indices by the possible total sum of Jaccard Indices. In this case, there are three sets, so the sum of the three Jaccard Indices is divided by 3. This value is subtracted from 1 to indicate difference rather than similarity.
calculate_situational_flexibility <- function(the_actor) {
set1 <- flex_frame |>
filter(actor == the_actor & question == "Q1") |>
select(actor, to) |>
as.data.frame()
set1$actor <- as.factor(set1$actor)
set1$to <- as.factor(set1$to)
set2 <- flex_frame |>
filter(actor == the_actor & question == "Q3") |>
select(actor, to) |>
as.data.frame()
set2$actor <- as.factor(set2$actor)
set2$to <- as.factor(set2$to)
set3 <- flex_frame |>
filter(actor == the_actor & question == "Q4") |>
select(actor, to) |>
as.data.frame()
set3$actor <- as.factor(set3$actor)
set3$to <- as.factor(set3$to)
jaccard_1 <- calculate_jaccard(set1, set2)
jaccard_2 <- calculate_jaccard(set2, set3)
jaccard_3 <- calculate_jaccard(set1, set3)
# the_flexibility <- 1 - ((1 / (3 * (3 - 1)) * (jaccard_1 + jaccard_2 + jaccard_3)) / 3)
the_flexibility <- 1 - ((jaccard_1 + jaccard_2 + jaccard_3) / 3)
response_frame <- data.frame(actor = the_actor, flexibility = the_flexibility)
return(response_frame)
}Processing The Data
Reading the Data
pates_frame <- import("https://osf.io/download/62qpa/", format = "csv") |>
mutate_all(toupper) |>
filter(id != "PA09") |>
pivot_longer(
cols = starts_with("Q"),
names_to = "question",
values_to = "to"
) |>
drop_na() |>
select("question", "from" = "id", "to") |>
separate(col = question, into = c("question", "order"), sep = "_") |>
filter(to != "")
write_csv(pates_frame, "output/csv/pates_frame.csv")
ncfl_frame <- import("https://osf.io/download/ghz3c/", format = "csv") |>
mutate_all(toupper) |>
pivot_longer(
cols = starts_with("Q"),
names_to = "question",
values_to = "to"
) |>
drop_na() |>
select("question", "from" = "ID", "to") |>
separate(col = question, into = c("question", "order"), sep = "_") |>
filter(to != "")
write_csv(ncfl_frame, "output/csv/ncfl_frame.csv")
full_frame <- rbind(pates_frame, ncfl_frame)Create Overall Graph
full_salience <- calculate_salience(full_frame, "GROUPING", "full")
full_graph <- set_graph(full_frame, full_salience)
full_plot <- draw_graph(full_graph, "full")
# A tibble: 80 × 4
question order from to
<chr> <chr> <chr> <chr>
1 Q1 1 PA01 UF01
2 Q3 1 PA01 US01
3 Q3 2 PA01 UF01
4 Q4 1 PA01 UF01
5 Q4 2 PA01 FF02
6 Q1 1 PA02 UF01
7 Q1 2 PA02 US02
8 Q3 1 PA02 UF01
9 Q3 2 PA02 US02
10 Q4 1 PA02 UF01
# ℹ 70 more rowsProcess Questions
pates_q1_frame <- pates_frame |>
filter(question == "Q1")
pates_q1_salience <- calculate_salience(pates_q1_frame, "GROUPING", "Q1")
pates_q1_graph <- set_graph(pates_q1_frame, pates_q1_salience)
pates_q1_plot <- draw_graph(pates_q1_graph, "q1_pates")
pates_q1_cent <- calculate_centrality(pates_q1_graph, pates_q1_salience, "q1_pates")
pates_q1_key <- calculate_keyactors(pates_q1_cent, "q1_pates")
pates_q1_key_plot <- plot_keyactors(pates_q1_key, "q1_pates")
ncfl_q1_frame <- ncfl_frame |>
filter(question == "Q1")
ncfl_q1_salience <- calculate_salience(ncfl_q1_frame, "GROUPING", "Q1")
ncfl_q1_graph <- set_graph(ncfl_q1_frame, ncfl_q1_salience)
ncfl_q1_plot <- draw_graph(ncfl_q1_graph, "q1_ncfl")
ncfl_q1_cent <- calculate_centrality(ncfl_q1_graph, ncfl_q1_salience, "q1_ncfl")
ncfl_q1_key <- calculate_keyactors(ncfl_q1_cent, "q1_ncfl")
ncfl_q1_key_plot <- plot_keyactors(ncfl_q1_key, "q1_ncfl")
pates_q3_frame <- pates_frame |>
filter(question == "Q3")
pates_q3_salience <- calculate_salience(pates_q3_frame, "GROUPING", "Q3")
pates_q3_graph <- set_graph(pates_q3_frame, pates_q3_salience)
pates_q3_plot <- draw_graph(pates_q3_graph, "q3_pates")
pates_q3_cent <- calculate_centrality(pates_q3_graph, pates_q3_salience, "q3_pates")
pates_q3_key <- calculate_keyactors(pates_q3_cent, "q3_pates")
pates_q3_key_plot <- plot_keyactors(pates_q3_key, "q3_pates")
ncfl_q3_frame <- ncfl_frame |>
filter(question == "Q3")
ncfl_q3_salience <- calculate_salience(ncfl_q3_frame, "GROUPING", "Q3")
ncfl_q3_graph <- set_graph(ncfl_q3_frame, ncfl_q3_salience)
ncfl_q3_plot <- draw_graph(ncfl_q3_graph, "q3_ncfl")
ncfl_q3_cent <- calculate_centrality(ncfl_q3_graph, ncfl_q3_salience, "q3_ncfl")
ncfl_q3_key <- calculate_keyactors(ncfl_q3_cent, "q3_ncfl")
ncfl_q3_key_plot <- plot_keyactors(ncfl_q3_key, "q3_ncfl")
pates_q4_frame <- pates_frame |>
filter(question == "Q4")
pates_q4_salience <- calculate_salience(pates_q4_frame, "GROUPING", "Q4")
pates_q4_graph <- set_graph(pates_q4_frame, pates_q4_salience)
pates_q4_plot <- draw_graph(pates_q4_graph, "q4_pates")
pates_q4_cent <- calculate_centrality(pates_q4_graph, pates_q4_salience, "q4_pates")
pates_q4_key <- calculate_keyactors(pates_q4_cent, "q4_pates")
pates_q4_key_plot <- plot_keyactors(pates_q4_key, "q4_pates")
ncfl_q4_frame <- ncfl_frame |>
filter(question == "Q4")
ncfl_q4_salience <- calculate_salience(ncfl_q4_frame, "GROUPING", "Q4")
ncfl_q4_graph <- set_graph(ncfl_q4_frame, ncfl_q4_salience)
ncfl_q4_plot <- draw_graph(ncfl_q4_graph, "q4_ncfl")
ncfl_q4_cent <- calculate_centrality(ncfl_q4_graph, ncfl_q4_salience, "q4_ncfl")
ncfl_q4_key <- calculate_keyactors(ncfl_q4_cent, "q4_ncfl")
ncfl_q4_key_plot <- plot_keyactors(ncfl_q4_key, "q4_ncfl")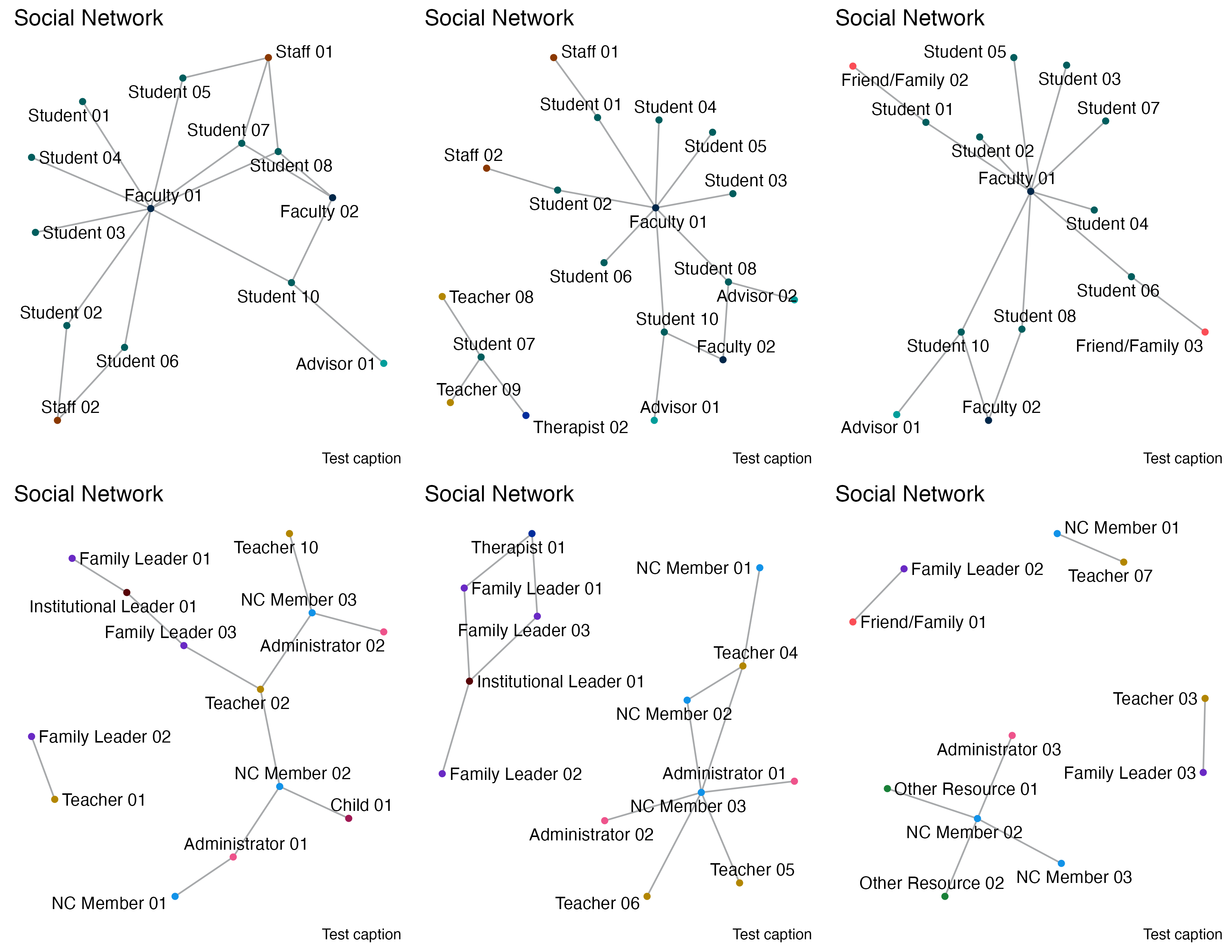
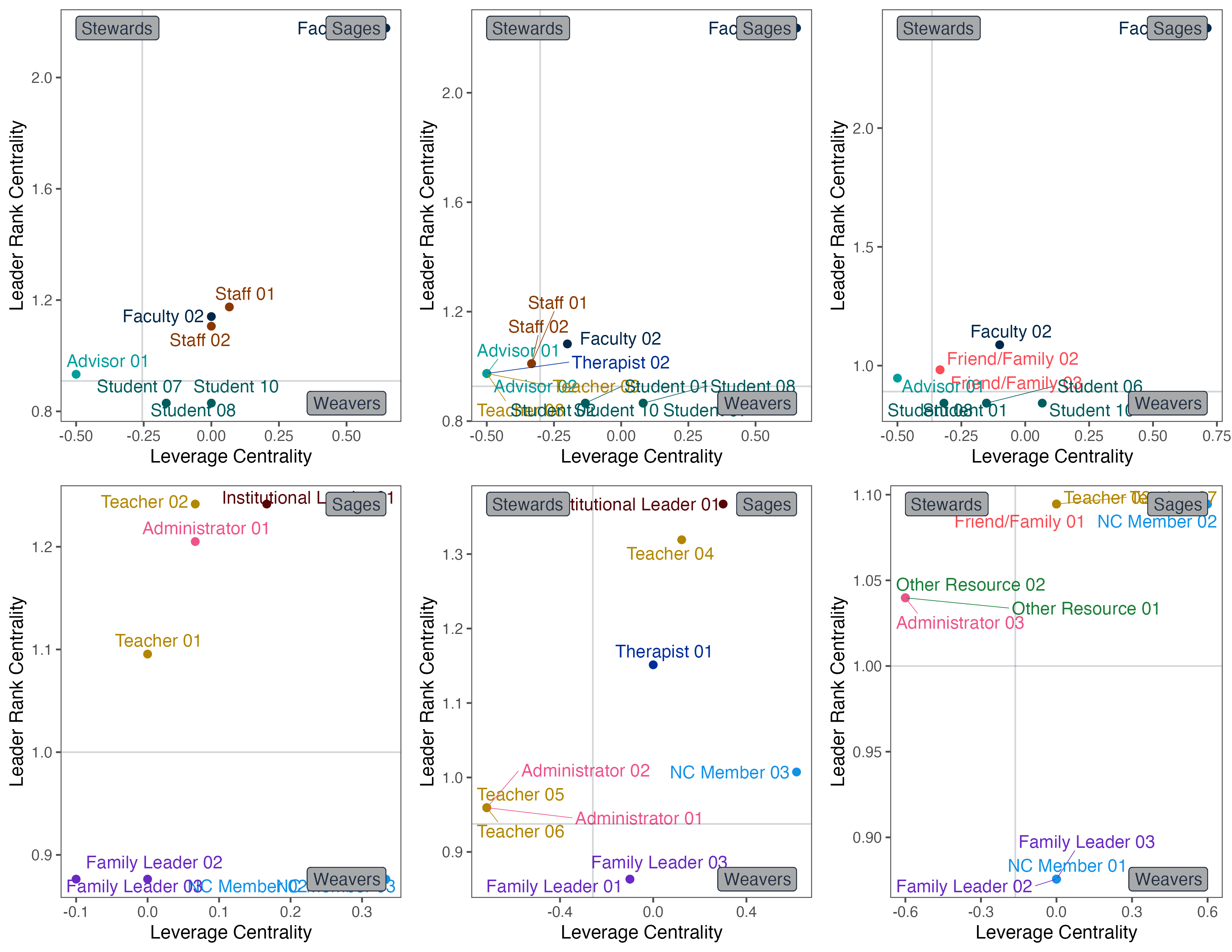
Analyzing the Data
Preparing the Scores
Calculate Actor Flexibility Score
Calculate Key Actor Score
q1_key <- create_q_key(pates_q1_key, ncfl_q1_key, "q1")
q3_key <- create_q_key(pates_q3_key, ncfl_q3_key, "q3")
q4_key <- create_q_key(pates_q4_key, ncfl_q4_key, "q4")
q_key <<- bind_rows(q1_key, q3_key, q4_key) |>
select(actor, keystatus) |>
mutate(keyscore = case_when(
keystatus == "Sage" ~ 3,
keystatus == "Steward" ~ 2,
keystatus == "Weaver" ~ 1
)) |>
group_by(actor) |>
summarize(keyscore = sum(keyscore)) |>
mutate(keyscore = keyscore / 9)Create Rankings for Comparing Across Graphs
Because this is a multilayered graph that includes information across a range of contexts in response to different prompts, the calculated centralities themselves cannot be compared because this is like comparing a golden delicious to a honey crisp apple. Instead, relative ranks can be compared across the multiple layers of the graphs: how did actor \(i\) rank compare to the others? This ranking provides a picture across contexts and prompts.
Blah blah blah.
q1_cent <- create_q_cent(pates_q1_cent, ncfl_q1_cent, "q1") |>
calculate_ranks()
q3_cent <- create_q_cent(pates_q3_cent, ncfl_q3_cent, "q3") |>
calculate_ranks()
q4_cent <- create_q_cent(pates_q4_cent, ncfl_q4_cent, "q4") |>
calculate_ranks()
q_cent <<- bind_rows(q1_cent, q3_cent, q4_cent)full_avg_cent <- q_cent |>
select(
actor, leverage_rank, laplacian_rank, outdegree_rank, indegree_rank,
latora_rank, leaderrank_rank, smiths_rank
) |>
group_by(actor) |>
summarize(across(everything(), mean), .groups = "drop") |>
left_join(flex_score) |>
left_join(q_key) |>
replace_na(list(flexibility = 0, keyscore = 0)) |>
mutate(flexibility_rank = dense_rank(desc(flexibility))) |>
mutate(keyscore_rank = dense_rank(desc(keyscore))) |>
ungroup() |>
as.data.frame()Analyze Key Actors
We look at the key actors in this project as contributors to the social network through three dimensions:
- Positionality. Laplacian Centrality and Leverage Centrality
- Reachability. Latora Closeness Centrality and In Degree Centrality
- Reputation. Leader Rank Centrality and Smith’s S Score
\(\frac{1}{{\text{avg}(R_{\text{p}},\ R_{\text{q}})}} \times 10\)
keyactors_q_frame <- q_key |>
left_join(q1_key) |>
left_join(q3_key, by = "actor") |>
left_join(q4_key, by = "actor") |>
select(actor,
q1_status = keystatus.x, q3_status = keystatus.y,
q4_status = keystatus
) |>
arrange(actor)
keyactors_frame <- full_avg_cent |>
filter(keyscore > 0) |>
mutate(positionality_score = ((1 / (laplacian_rank + leverage_rank) / 2)) * 10) |>
mutate(reputation_score = ((1 / (smiths_rank + leaderrank_rank) / 2)) * 10) |>
mutate(reachability_score = ((1 / (latora_rank + indegree_rank) / 2)) * 10) |>
mutate(overall_score = (positionality_score + reputation_score + reachability_score) / 3) |>
select(
actor, overall_score, positionality_score, reachability_score, reputation_score,
keyscore, keyscore_rank
) |>
left_join(keyactors_q_frame) |>
unique() |>
arrange(desc(overall_score))
write_csv(keyactors_frame, file = "output/csv/keyactors_analysis.csv")| actor | overall_score | Network Scores | Key Actor Roles | ||||
|---|---|---|---|---|---|---|---|
| positionality_score | reachability_score | reputation_score | q1_status | q3_status | q4_status | ||
| UF01 | 2.2916667 | 2.5000000 | 2.5000000 | 1.8750000 | Sage | Sage | Sage |
| ST02 | 0.9074074 | 0.5000000 | 0.5555556 | 1.6666667 | Sage | ||
| ST04 | 0.6144781 | 0.5555556 | 0.4545455 | 0.8333333 | Sage | ||
| UF02 | 0.5728692 | 0.3846154 | 0.6818182 | 0.6521739 | Sage | Sage | Sage |
| IL01 | 0.5708333 | 0.4000000 | 0.3125000 | 1.0000000 | Sage | Sage | |
| OR01 | 0.5702614 | 0.2941176 | 0.4166667 | 1.0000000 | Steward | ||
| PA10 | 0.5430791 | 0.6250000 | 0.7500000 | 0.2542373 | Weaver | Weaver | Weaver |
| PA08 | 0.4895077 | 0.5000000 | 0.7142857 | 0.2542373 | Weaver | Weaver | Weaver |
| OR02 | 0.4750233 | 0.2941176 | 0.4166667 | 0.7142857 | Steward | ||
| US01 | 0.4480820 | 0.3125000 | 0.4761905 | 0.5555556 | Sage | Steward | |
| SA03 | 0.4221133 | 0.2941176 | 0.4166667 | 0.5555556 | Steward | ||
| FF02 | 0.4162210 | 0.2941176 | 0.5000000 | 0.4545455 | Sage | ||
| FF03 | 0.4162210 | 0.2941176 | 0.5000000 | 0.4545455 | Sage | ||
| FF01 | 0.4139194 | 0.3571429 | 0.3846154 | 0.5000000 | Sage | ||
| ST03 | 0.4139194 | 0.3571429 | 0.3846154 | 0.5000000 | Sage | ||
Analyze Participant Actors
We look at the participants in this project–the Pre-Admissions Teacher Education Students, the Neighborhood Caucus members, and the Family Leaders–as contributors to the social network through three perspectives (really need to come up with a better word than that):
- Positionality. Laplacian Centrality and Leverage Centrality
- Reachability. Latora Closeness Centrality and Out Degree Centrality
- Potentiality. Flexibility Score and Reputation Score
key_reputation <- keyactors_frame |>
select(actor, reputation_score)
participants_frame <- full_avg_cent |>
left_join(key_reputation) |>
filter(substr(actor, 1, 2) == "PA" | substr(actor, 1, 2) == "FL" | substr(actor, 1, 2) == "NC") |>
mutate(reputation_rank = dense_rank(desc(reputation_score))) |>
replace_na(list(reputation_rank = 0))
reputation_rank_na <- (max(participants_frame$reputation_rank)) + 1
participants_frame <- participants_frame |>
mutate(reputation_rank = if_else(reputation_rank == 0, reputation_rank_na, reputation_rank)) |>
mutate(potentiality_score = ((1 / (flexibility_rank + reputation_rank) / 2)) * 10) |>
mutate(positionality_score = ((1 / (laplacian_rank + leverage_rank) / 2)) * 10) |>
mutate(reachability_score = ((1 / (latora_rank + outdegree_rank) / 2)) * 10) |>
# mutate(potentiality_score = (((flexibility_rank + reputation_rank) / 2))) |>
# mutate(positionality_score = (((laplacian_rank + leverage_rank) / 2))) |>
# mutate(reachability_score = (((latora_rank + outdegree_rank) / 2))) |>
mutate(
overall_score =
(potentiality_score +
positionality_score +
reachability_score)
/ 3
) |>
select(
actor,
overall_score,
positionality_score,
reachability_score,
potentiality_score,
laplacian_rank,
leverage_rank,
latora_rank,
outdegree_rank,
flexibility_rank,
keyscore_rank,
reputation_rank
) |>
arrange(desc(overall_score)) |>
as.data.frame()
write_csv(participants_frame,
file = "output/csv/participants_analysis.csv"
)| actor | overall_score | positionality_score | reachability_score | potentiality_score |
|---|---|---|---|---|
| NC03 | 0.9007937 | 0.5000000 | 0.5357143 | 1.6666667 |
| NC02 | 0.8730959 | 0.4838710 | 0.4687500 | 1.6666667 |
| PA10 | 0.8472222 | 0.6250000 | 1.5000000 | 0.4166667 |
| PA08 | 0.7500000 | 0.5000000 | 1.2500000 | 0.5000000 |
| NC01 | 0.5966731 | 0.2459016 | 0.2941176 | 1.2500000 |
| FL02 | 0.5921593 | 0.2586207 | 0.2678571 | 1.2500000 |
| PA07 | 0.5584156 | 0.4054054 | 0.5555556 | 0.7142857 |
| PA06 | 0.5547261 | 0.3191489 | 0.7894737 | 0.5555556 |
| PA01 | 0.5438808 | 0.3260870 | 0.7500000 | 0.5555556 |
| PA02 | 0.5404040 | 0.3333333 | 0.8333333 | 0.4545455 |
| FL03 | 0.4952719 | 0.3191489 | 0.3333333 | 0.8333333 |
| PA05 | 0.4588930 | 0.2777778 | 0.7142857 | 0.3846154 |
| PA03 | 0.4023810 | 0.2500000 | 0.6000000 | 0.3571429 |
| PA04 | 0.4023810 | 0.2500000 | 0.6000000 | 0.3571429 |
| FL01 | 0.3539886 | 0.2500000 | 0.2564103 | 0.5555556 |
Initial Reflections

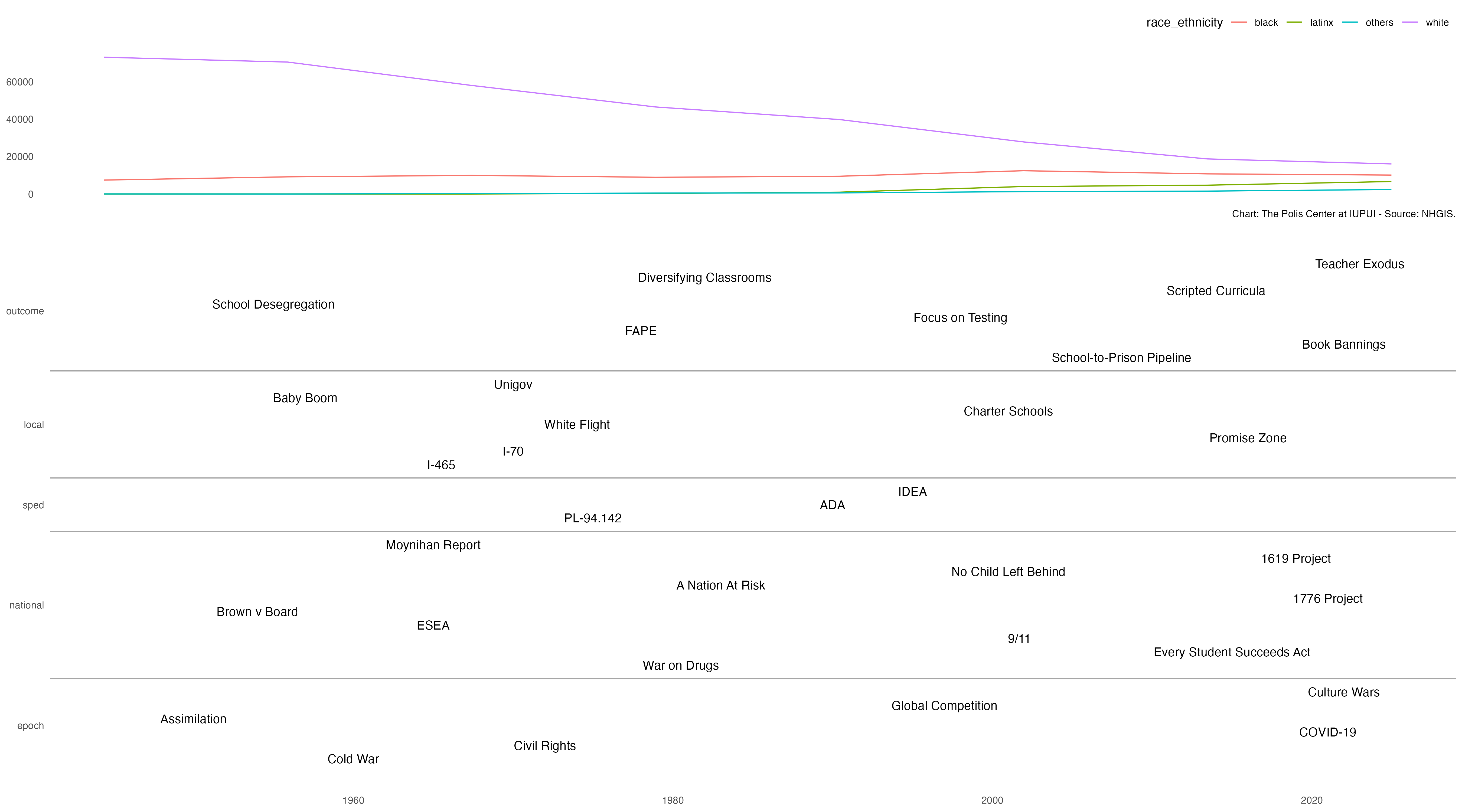
Providing Context
Unruly complexity comes from the work of Peter Taylor through his critique of models and his efforts to re-situate model-based research in historical and sociocultural contexts (Taylor 2010, 2018).
Consider Sociocultural Ontological and Phenomenological Contexts
Ontological contexts refer to structural and infrastructural elements of social life.
Phenomenological contexts refer to personal experiential considerations.
(Dörpinghaus et al. 2022; Porter, Onnela, and Mucha 2009)
- Ontological
- White Flight
- Focus on Testing
- SoE Mission and Vision
- FAPE
- Phenomenological
- Educator Preparation
- Schooling Experiences
- Learning Agendas (Ash 2003)
Ontological and phenomenological contexts can inform one another, for example
FAPE and Schooling Experiences inform Learning Agendas but we consider
these separately.
Consider Sociohistorical Context
Acknowledgments
This is work is funded in part by a National Association for Family, School, and Community Engagement (NAFSCE) Mini-Grant. Appreciation to Harish Gadde and Jay Colbert of the Polis Center at IUPUI for providing the historical census data.
Author Contributions
| Role | Authors |
|---|---|
| Conceptualization | Jeremy F Price, Cristinia Santamaría Graff |
| Data Curation | Jeremy F Price, Cristinia Santamaría Graff, Akaash Arora, Amy Waechter-Versaw, Román Graff |
| Formal Analysis | Jeremy F Price, Cristinia Santamaría Graff, Akaash Arora, Amy Waechter-Versaw, Román Graff |
| Funding Acquisition | Cristinia Santamaría Graff, Jeremy F Price |
| Investigation | Jeremy F Price, Cristinia Santamaría Graff |
| Methodology | Jeremy F Price |
| Project Administration | Cristinia Santamaría Graff, Jeremy F Price |
| Software | Jeremy F Price |
| Supervision | Jeremy F Price |
| Visualization | Jeremy F Price |
| Writing - Original Draft | Jeremy F Price, Cristinia Santamaría Graff, Akaash Arora, Amy Waechter-Versaw, Román Graff |
| Writing - Review & Editing | Jeremy F Price, Cristinia Santamaría Graff, Akaash Arora, Amy Waechter-Versaw, Román Graff |
| Available in JATS format. | |
Session Information
The session information is provided for reproducibility purposes.
─ Session info ─────────────────────────────────────────────────────
setting value
version R version 4.3.1 (2023-06-16)
os macOS Sonoma 14.1.2
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/Indiana/Indianapolis
date 2023-12-16
pandoc 3.1.1 @ /Applications/RStudio.app/Contents/Resources/app/quarto/bin/tools/ (via rmarkdown)
─ Packages ─────────────────────────────────────────────────────────
package * version date (UTC) lib source
AnthroTools * 0.8 2023-05-10 [1] Github (alastair-JL/AnthroTools@2475c3a)
centiserve * 1.0.0 2017-07-15 [1] CRAN (R 4.3.0)
dplyr * 1.1.3 2023-09-03 [1] CRAN (R 4.3.0)
ggcorrplot * 0.1.4 2022-09-27 [1] CRAN (R 4.3.0)
ggplot2 * 3.4.3 2023-08-14 [1] CRAN (R 4.3.0)
ggpubr * 0.6.0 2023-02-10 [1] CRAN (R 4.3.0)
ggraph * 2.1.0 2022-10-09 [1] CRAN (R 4.3.0)
ggthemes * 4.2.4 2021-01-20 [1] CRAN (R 4.3.0)
glue * 1.6.2 2022-02-24 [1] CRAN (R 4.3.0)
gt * 0.9.0 2023-03-31 [1] CRAN (R 4.3.0)
igraph * 1.5.1 2023-08-10 [1] CRAN (R 4.3.0)
Matrix * 1.6-1 2023-08-14 [1] CRAN (R 4.3.0)
readr * 2.1.4 2023-02-10 [1] CRAN (R 4.3.0)
rio * 0.5.29 2021-11-22 [1] CRAN (R 4.3.0)
tidygraph * 1.2.3 2023-02-01 [1] CRAN (R 4.3.0)
tidyr * 1.3.0 2023-01-24 [1] CRAN (R 4.3.0)
vistime * 1.2.3 2022-10-16 [1] CRAN (R 4.3.0)
[1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library
────────────────────────────────────────────────────────────────────